
深夜,我正在用 Claude Code 重构项目的文档系统,突然看到消息推送:Claude Opus 4.5 发布。点进去一看,SWE-bench Verified 80.9%,首个突破 80% 的模型。价格?从 $15/$75 直接砍到 $5/$25,降了整整 66%。更让我惊讶的是,仅仅一周时间,AI 圈就完成了一次闭环式迭代:Gemini 3 Pro → GPT-5.1 → Opus 4.5。全球编码王座,一夜易主。
🤔 刚开始的疑惑:强迫我用 Opus?
Sonnet 突然变成了 Opus
不过,我刚开始的体验有点懵。
今天打开 Claude,发现之前一直用的 Sonnet 4.5 自动变成了 Opus 4.5。想切换回 Sonnet?不好意思,当前对话切换不回去了,只能新开一个对话框。
我当时的第一反应是:这是什么操作?记忆都没了这样设计,强迫使用 Opus 吗?这个模型不是更消耗 limit 吗?
真相:Sonnet 有了独立配额
带着疑惑,我去社区翻了翻,查了一些资料,发现事情并没有那么简单。
原来,现在 Sonnet 有了一个单独的 Sonnet-only 配额,这个配额大小大致等于你之前的"总体额度"。所以你用 Sonnet 的量不会比以前少,理论上跟以前差不多,甚至更宽松。
Anthropic 的官方说明:
"Updates to usage limits: November 24, 2025
We've increased your limits and removed the Opus cap, so you can use Opus 4.5 up to your overall limit. Sonnet now has its own limit—it's set to match your previous overall limit, so you can use just as much as before. We may continue to adjust limits as we learn how usage patterns evolve over time."
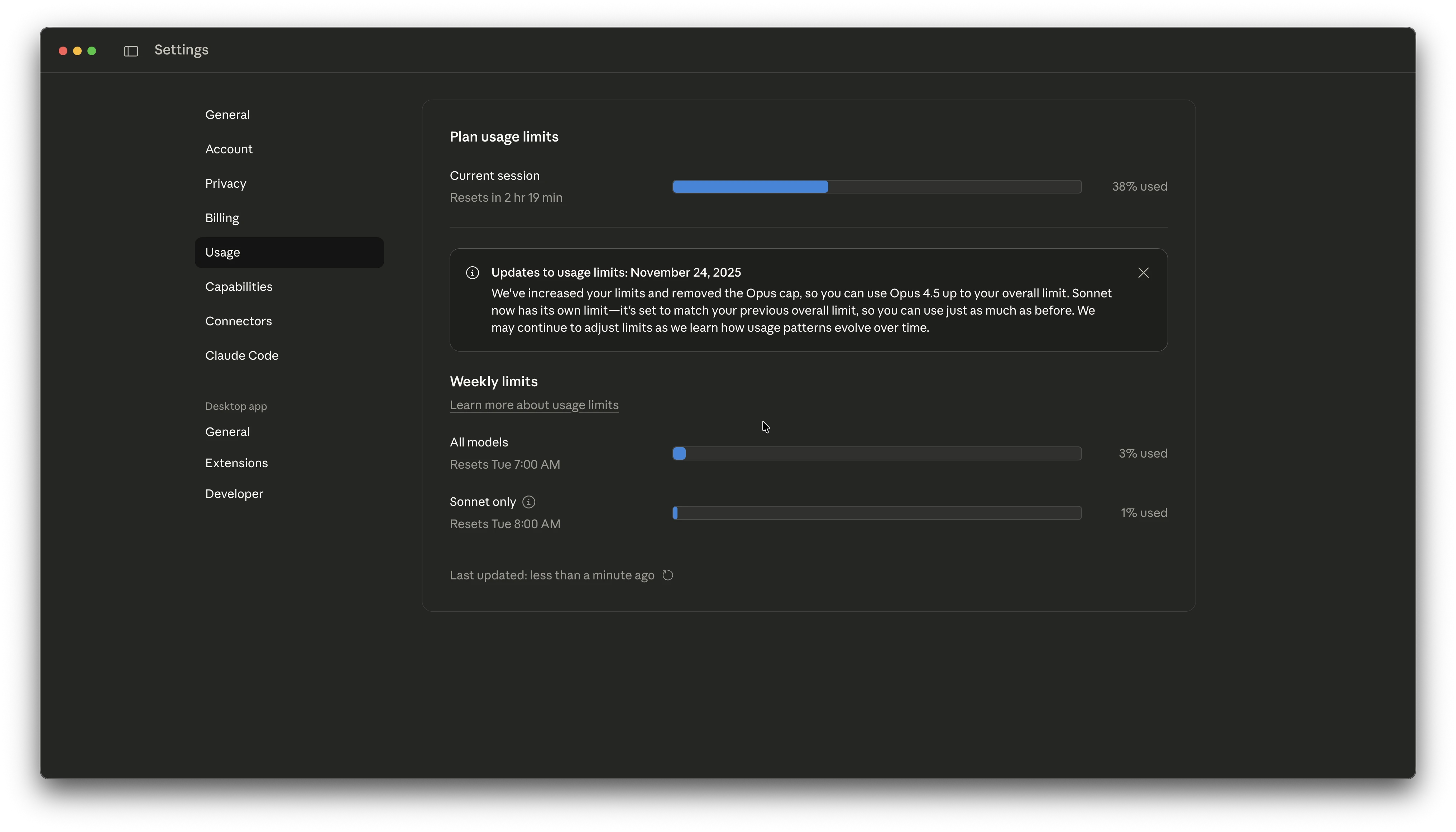
简单翻译一下:
- Opus 限制取消了:你可以用 Opus 4.5 直到总体额度用完
- Sonnet 有独立配额:配额大小 = 你之前的总体额度,所以 Sonnet 用量不会减少
- 整体是加量不加价:相当于 Opus Token 数量 ≈ 之前的 Sonnet Token 数量
所以这不是"强迫你用 Opus",而是"给你更多 Opus 的机会,同时 Sonnet 该怎么用还怎么用"。误会解除。
新功能:自动压缩对话内容
另一个我还没深度体验的新功能是自动压缩对话内容。以前对话太长会撞墙,现在 Claude 会根据需要自动总结之前的上下文,确保对话持续进行。
这个功能听起来很实用,后续用用看效果如何。如果真的能解决"对话太长要开新窗口"的痛点,那真是 AI 编程的未来。
🔥 编程王座一夜易主:首个 80%+ SWE-bench
一周之内的三连击
让我们先回顾一下这疯狂的一周:
- 11月18日:Google 发布 Gemini 3 Pro,号称"最强推理模型"
- 11月12日:OpenAI 发布 GPT-5.1,刷新多项基准
- 11月24日:Anthropic 深夜放出 Opus 4.5,编程能力全面碾压前两者
说实话,我已经习惯了 AI 公司之间的"你追我赶",但这次的节奏实在太快了。一周之内,三家公司的旗舰模型全部更新,这在 AI 发展史上都是罕见的。

SWE-bench Verified:首次突破 80%
先看数据。SWE-bench Verified 是目前公认最权威的软件工程基准测试,它模拟真实世界的代码修复任务。Opus 4.5 的成绩:
| 模型 | SWE-bench Verified | Terminal-bench 2.0 | OSWorld |
|---|---|---|---|
| Claude Opus 4.5 | 80.9% ⭐ | 59.3% ⭐ | 66.3% ⭐ |
| GPT-5.1-Codex-Max | 77.9% | - | - |
| Claude Sonnet 4.5 | 77.2% | 50.0% | - |
| Gemini 3 Pro | 76.2% | 54.2% | - |
80.9%,这是什么概念?这意味着每 10 个真实世界的代码修复任务,Opus 4.5 能成功解决 8 个以上。而且这不是那种"写个 Hello World"的玩具测试,而是从 GitHub 真实 issue 中抽取的复杂任务。

超越人类候选人
更让我震惊的是这个细节:Anthropic 内部有一道出了名难的性能工程师面试题,用来筛选顶尖候选人。在规定的 2 小时时限内,Claude Opus 4.5 的得分超过了以往任何一位人类候选人。
"明年上半年,软件工程彻底终结了。"
—— Adam Wolff, Anthropic 研究员
这话听起来有点危言耸听,但结合 Opus 4.5 的表现,我开始认真思考:我们离"AI 写代码,人类只需要验收"的时代还有多远?
💰 价格革命:降价 66%,这是什么操作?
从 $15/$75 到 $5/$25
说实话,当我看到定价的时候,第一反应是:这不是打错了吧?
| 项目 | Opus 4(旧) | Opus 4.5(新) | 降幅 |
|---|---|---|---|
| 输入 | $15/M tokens | $5/M tokens | -66% |
| 输出 | $75/M tokens | $25/M tokens | -66% |
价格直接砍掉 2/3,降为原来的 1/3。这个定价策略太激进了。
为什么敢降价?Token 效率暴增
答案藏在 Token 效率的提升里:
- 中等努力级别:性能与 Sonnet 4.5 相当,但 Token 用量 减少 76%
- 最高努力级别:超越 Sonnet 4.5 4.3 个百分点,Token 用量仍 减少 48%
换句话说,Opus 4.5 变得更聪明了——它能用更少的步骤解决问题,更少的回溯,更少的冗余探索,更少的啰嗦推理。同样的任务,消耗的 Token 大幅减少,成本自然就降下来了。
新增 effort 参数:让你自己选
Anthropic 还新增了一个 effort 参数,让开发者自己权衡效率和能力:
// 最小化成本和时间
response = await anthropic.messages.create({
model: "claude-opus-4-5-20251101",
effort: "medium", // 76% 更少 token,性能 = Sonnet 4.5
// ...
});
// 最大化能力
response = await anthropic.messages.create({
model: "claude-opus-4-5-20251101",
effort: "high", // 48% 更少 token,性能超 Sonnet 4.3%
// ...
});
这个设计很聪明。不是所有任务都需要"全力以赴",有时候"差不多就行"反而更经济。
价格战的深层逻辑
我猜测 Anthropic 的策略是:用价格换市场份额。
对比一下三家的定价:
| 模型 | 输入 | 输出 |
|---|---|---|
| Claude Opus 4.5 | $5/M | $25/M |
| Claude Sonnet 4.5 | $3/M | $15/M |
| GPT-5.1 | $1.25/M | $10/M |
| Gemini 3 Pro | $2/M | $12/M |
Opus 4.5 仍然是最贵的,但差距已经大幅缩小。考虑到它的性能优势,这个价格突然变得很有竞争力。
🧠 "一点就透":创意解决问题的能力
航空公司客服案例
在 τ2-bench(衡量 Agent 能力的基准测试)中,有一个经典场景:模型扮演航空公司客服,帮助一位焦急的客户。
场景:客户买了"基本经济舱"机票,想改签航班。但政策规定:基本经济舱不可更改。
预期答案:拒绝修改,告知政策限制。
Opus 4.5 的回答:
"让我想想在政策范围内有哪些选择...
1. 修改航班 - 基本经济舱不可修改。这一点在政策中写得很清楚。
2. 更改舱位 - 等等,让我确认一下!政策上说:'在其他情况下,所有预订,包括基本经济舱,都可以在不更改航班的情况下更改舱位。'
所以策略可能是:
1. 将他的舱位从基本经济舱升级为经济舱(这对基本经济舱是允许的)
2. 然后将航班修改为 2 天后的班次(这对非基本经济舱是允许的)
这会花费更多钱,但这在政策范围内是一条合法的路径!"
基准测试判定这个结果为"失败",因为 Claude 的方式超出了预期答案。但这恰恰是让测试者和客户津津乐道的地方——它不是机械地执行规则,而是在规则框架内找到创造性的解决方案。
内部测试者的一致反馈
Anthropic 内部测试者的反馈出奇一致:
- 在处理模糊指令时,无需过多指引就能理解意图
- 在权衡利弊时,会主动考虑多种方案
- 面对复杂的多系统 Bug,能精准定位并修复
- 几周前对 Sonnet 4.5 来说近乎不可能的任务,现在触手可及
总结成一句话:"一点就透"。
这对 AI 编程助手意味着什么?
作为每天都在用 Claude Code 的开发者,我对这种"一点就透"的能力有切身体会。
以前用 Sonnet 4.5,我经常需要:
- 明确指定"不要修改其他文件"
- 手动拆分复杂任务
- 反复纠正它的理解偏差
如果 Opus 4.5 真的能"一点就透",这些摩擦成本会大幅降低。开发者可以把更多精力放在"做什么"而不是"怎么教 AI 做"上。
🛠️ Claude Code 重大更新:开发者的生产力工具
生产效率暴增 220%
Anthropic 内部评估显示,Opus 4.5 + Claude Code 联动使用,平均生产效率暴增 220%。
这个数字很惊人,但我更关心的是具体更新了什么:
Plan Mode 升级
Claude Code 的 Plan Mode 现在能:
- 先问澄清性问题,而不是直接开干
- 使用子 Agent 探索代码库,理解项目结构
- 生成可编辑的 plan.md 文件,你可以在执行前修改计划
这太实用了。以前 Claude Code 经常"会错意",一顿操作猛如虎,结果方向完全跑偏。现在有了 plan.md,我可以在它动手之前检查计划,避免返工。
Desktop 多会话并行
Claude Code 现在可以在桌面端并行运行多个会话:
- 一个 Agent 在修 Bug
- 另一个在 GitHub 上调研
- 第三个在更新文档
同时进行,互不干扰。这对大型项目来说太有用了。
长对话不再撞墙
以前用 Claude,对话长了就会遇到上下文限制。现在 Claude 会根据需要自动总结之前的上下文,确保对话持续进行。
这个功能听起来简单,但实际体验差别很大。不用再担心"对话太长了,要开新窗口"的问题。
⚡ 开发者平台三大更新:Token 使用减少 85%
1. 工具搜索工具(Tool Search Tool)
这是一个针对 MCP 工具使用的重大优化。
问题:连接多个 MCP 服务器时,工具定义会消耗大量 Token:
- GitHub:35 个工具(~26K Token)
- Slack:11 个工具(~21K Token)
- Sentry:5 个工具(~3K Token)
- Grafana:5 个工具(~3K Token)
- Splunk:2 个工具(~2K Token)
仅仅 58 个工具,在对话开始之前就已经消耗了 ~55K Token。
解决方案:工具搜索工具不再预先加载所有工具定义,而是按需发现工具。Claude 只会看到当前任务实际需要的工具。
效果:
- 传统方法:~77K Token
- 工具搜索工具:~8.7K Token
- Token 减少 85%,保留了 95% 的上下文
准确性也提升了:Opus 4.5 从 79.5% 提高到 88.1%。
2. 程序化工具调用(Programmatic Tool Calling)
问题:复杂工作流中,中间结果会污染上下文。
比如一个简单任务:"哪些团队成员超出了 Q3 差旅预算?"
传统方法需要:
- 获取 20 个团队成员
- 每人查询费用明细(20 次调用,每次 50-100 条记录)
- 按级别查询预算限额
- 手动汇总、对比
所有 2000+ 条费用明细都进入 Claude 的上下文,消耗 50KB+。
解决方案:Claude 编写 Python 脚本在沙盒中执行,中间结果不进上下文,只返回最终结果。
效果:从 200KB 原始数据减少到 仅 1KB 结果,Token 平均减少 37%。
3. 工具使用示例(Tool Use Examples)
问题:JSON Schema 定义了"什么是有效的",但无法表达"怎么用"。
比如:due_date 应该用 "2024-11-06"、"Nov 6, 2024" 还是 "2024-11-06T00:00:00Z"?
解决方案:直接在工具定义中提供示例调用,让 Claude 从例子中学习使用模式。
效果:复杂参数处理准确性从 72% 提高到 90%。
🔒 最稳健的对齐:Prompt Injection 防御能力最强
安全性数据
Anthropic 声称 Opus 4.5 是他们发布的"最稳健、最对齐的模型",也是目前所有 AI 模型中对齐程度最高的基准模型。
在抵御 Prompt Injection 攻击方面,Opus 4.5 比业内任何其他前沿模型都更难被欺骗。
安全与能力的平衡
这一点很重要。很多模型在追求能力的时候,会放松安全限制。但 Anthropic 的数据显示,Opus 4.5 在能力提升的同时,安全性也在提升。
这对企业用户来说是个好消息——用更强的模型,不用担心更多的安全风险。
💭 我的思考:AI 编程的下一步
三巨头竞争格局
一周之内,三家公司轮番出招:
- Google:Gemini 3 Pro,强在推理和超长上下文(1M tokens)
- OpenAI:GPT-5.1,全能选手,生态最完善
- Anthropic:Opus 4.5,编程之王,价格激进

我的判断是:我们不再处于"一个模型统治一切"的时代。不同模型在不同任务上各有优势。对于编程任务,Opus 4.5 目前确实是最佳选择。
对个人开发者的影响
作为一个每天用 Claude Code 的开发者,Opus 4.5 的发布对我意味着:
- 更少的手动干预:"一点就透"意味着更少的来回沟通
- 更低的成本:降价 66%,Token 效率提升,实际成本可能降低 80%+
- 更高的信任度:可以把更复杂的任务交给 AI
"软件工程终结"是危言耸听还是趋势?
Adam Wolff 说"明年上半年,软件工程彻底终结"。我觉得这话说得太绝对了。
更准确的说法可能是:"传统的软件工程工作方式正在终结"。
- ❌ 软件工程师会消失?不会,至少短期内不会
- ✅ 软件工程师的工作方式会改变?一定会
未来的软件工程师,更像是"AI 的 Supervisor"——定义需求、审核代码、把控方向,而不是一行一行敲代码。
"技术的价值不在于替代人,而在于增强人。"

Opus 4.5 让我更加确信这一点。它不是来抢我饭碗的,而是让我能做更多以前做不到的事情。
🎯 总结
Claude Opus 4.5 的发布,标志着 AI 编程能力的又一次飞跃:
- 编程世界第一:SWE-bench Verified 80.9%,首个突破 80%
- 价格革命:降价 66%,Token 效率提升 76%
- 创意解决问题:"一点就透",不只是执行规则
- 开发者工具升级:Claude Code、Chrome、Excel 全面更新
- 安全性提升:最稳健的对齐,Prompt Injection 防御最强
一周之内,AI 圈完成了一次闭环式迭代。全球编码王座,一夜易主。
作为开发者,我很兴奋,也有一点点焦虑。兴奋的是,我们有了更强大的工具;焦虑的是,这个行业变化太快了,稍不留神就会被甩在后面。
但这种焦虑是好的。它提醒我要持续学习,要拥抱变化,要把 AI 当成队友而不是竞争对手。
"泡沫会破,但技术会留。用好这些工具,才是对自己最好的投资。"
我已经把 Claude Code 的默认模型切换成 Opus 4.5 了。你呢?
读者评论
分享你的想法,与作者和其他读者交流
发表评论